
The ability to quickly build and test new solutions is a key determinant of success for any tech company.
Cloud service providers like AWS allow us — software engineers and DevOps — to develop and implement new applications at a very fast pace.
Our development team recently conducted an internal project whereby we built a working minimum viable product (MVP) of an ad exchange — a piece of advertising technology that facilitates the buying and selling of online ads via real-time bidding auctions.
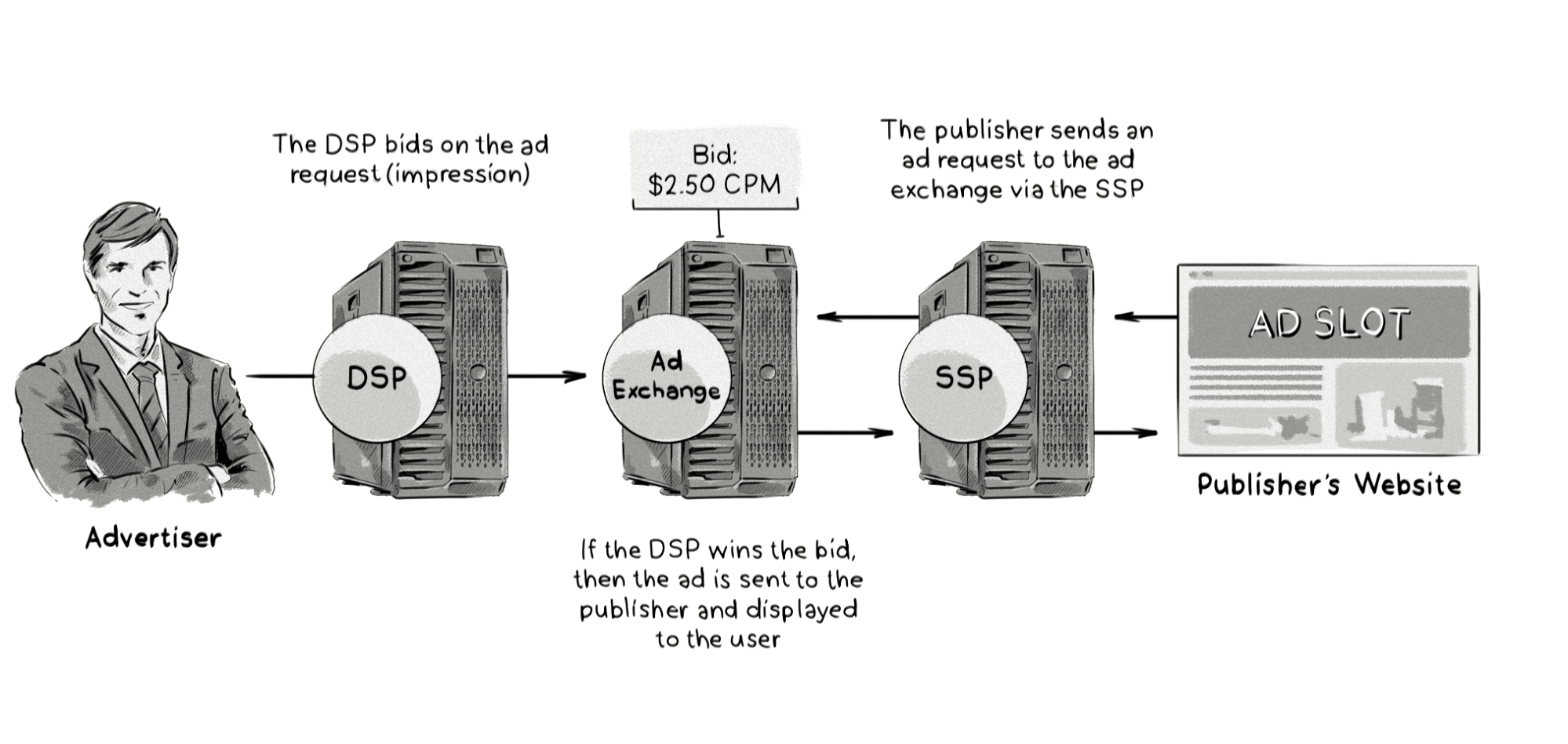
Ad exchanges emerged in the late 2000s with the introduction of real-time bidding (RTB). At first, they were standalone platforms that sat between demand-side platforms (DSPs) and supply-side platforms (SSPs).
However, over the past few years, many SSPs have incorporated exchange capabilities into their product and many ad exchanges have added features found in SSPs (e.g. inventory management and yield optimization).
In this post, we refer to an ad exchange as a component of an SSP, but it can also operate as a standalone platform.
About Our Project
A few things to highlight:
- We only used AWS services and chose managed services when we could.
- We built the ad exchange using the least amount of code possible.
- We wanted to be able to run reports by applying any date range and attribute filters (e.g. device, domain etc.) and break them down by any dimension available (any attribute) with the option to add sub-dimensions.
- Logs are stored on S3 in parquet format.
- The data volume is 10 to 20 billion auctions per day.
- No real-time reporting is included.
- We optimized costs where possible.
- We load and report on part of the data (e.g. the current week, month), and then we archive the data to save on costs.
To explain how we achieved this, we’ve divided this article into four parts:
- Visitor: Data gathered about visitor actions.
- Processing: Based on what the visitor generated, we create a data model that is complementary to the business’s needs. All enrichments take place here.
- Tracking pixel: Collect data from the ad request.
- Post processing: Make the collected data available to external tools.
We Can Help You Build an Ad Exchange
Our AdTech development teams can work with you to design, build, and maintain a custom-built ad exchange for any programmatic advertising channel.
Visitor
This part, as the name suggests, relates to the visitor and the decision-making process that goes into showing them an ad when they visit a web page.
When a web page starts loading, information about the visitor (geolocation, device model, etc.) is passed to the ad exchange either by collecting it directly from the publisher’s website or via a supply-side platform (SSP).
The ad exchange then passes this information to demand-side platforms (DSPs). This is known as a bid request.
If the advertiser operating the DSP wishes to display an ad to that user, they return a bid response to the ad exchange. If their bid is the highest, their ad is displayed to the user.
Internet users may notice that ads are displayed at the same time as other pieces of content, giving the false impression that this ad-serving process is somewhat simple.
However, serving an ad to a visitor is an extremely time-sensitive process — typically, an ad exchange needs to send out the bid request to other AdTech platforms in under 50ms.
Sending these requests to external systems (e.g. DSPs) in real time requires an extremely fast processing application.
Here’s a detailed description of this process and how it relates to the AWS services:
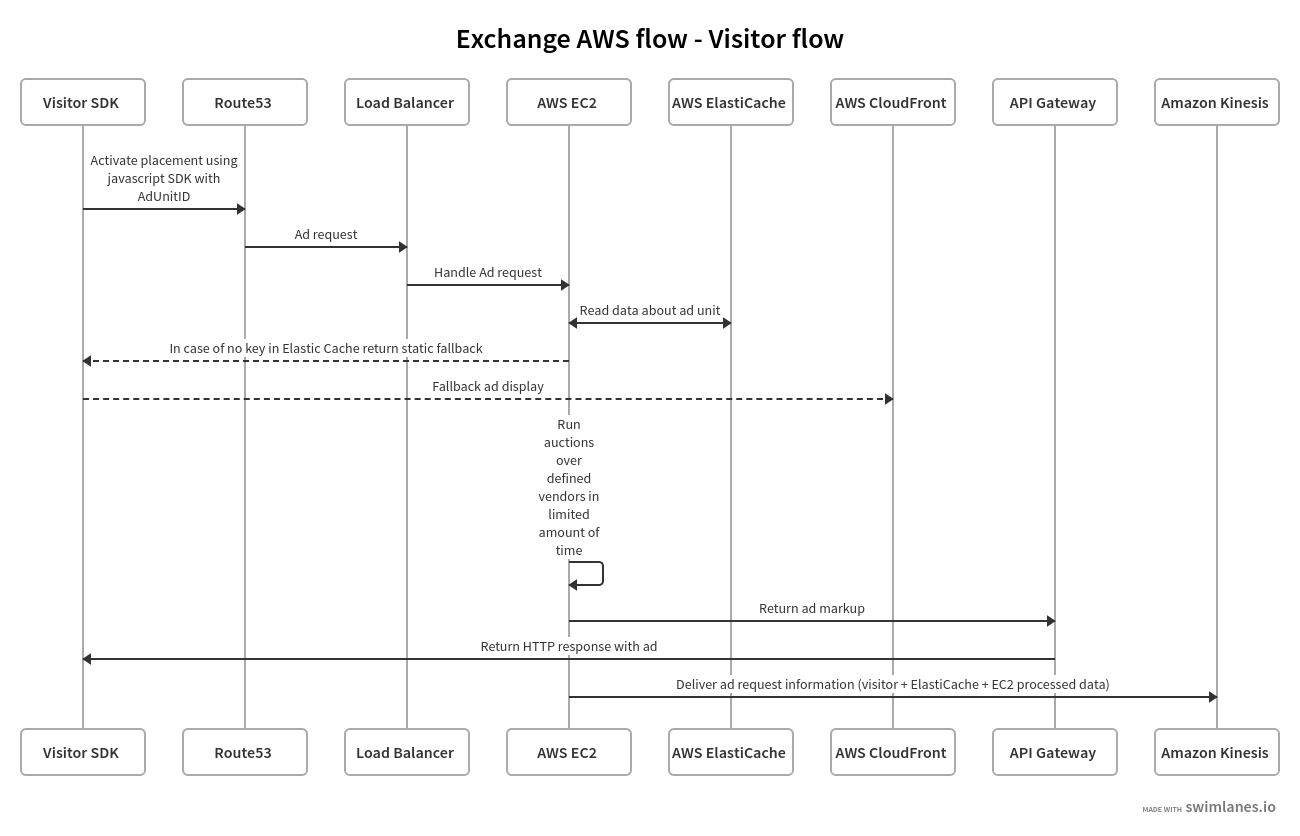
Here’s an overview of what happens:
- When a user visits a web page (e.g. http://example.com, which is typically served via a CDN or load balancer), a JavaScript SDK with a configured AdUnitID is activated.
- The configured DNS record points the SDK request to the load balancer (e.g. ALB) which in turn sends a request to EC2 instances (C or R instance types are recommended).
- To speed up the ad-serving process, an ElastiCache instance is used together with in-memory cache.
- The exchange system (an EC2 instance) queries in-memory cache with a fallback to ElastiCache.
- When no AdUnitID is found, some fallback ad is sent back and displayed to the visitor.
- If AdUnitID is found, an EC2 instance executes an auction between defined vendor(s) — typically DSPs and ad networks — in a limited amount of time (usually under 250ms). This can be one vendor or multiple vendors.
- The winning vendor then sends the ad markup to the browser and displays the ad to the visitor.
- While the ad is being displayed, all information gathered about the visitor and the ad itself are passed to Kinesis for further processing.
Processing
In this part, we gather data provided by the visitor (from the bid request) and enrich it to meet various business needs.
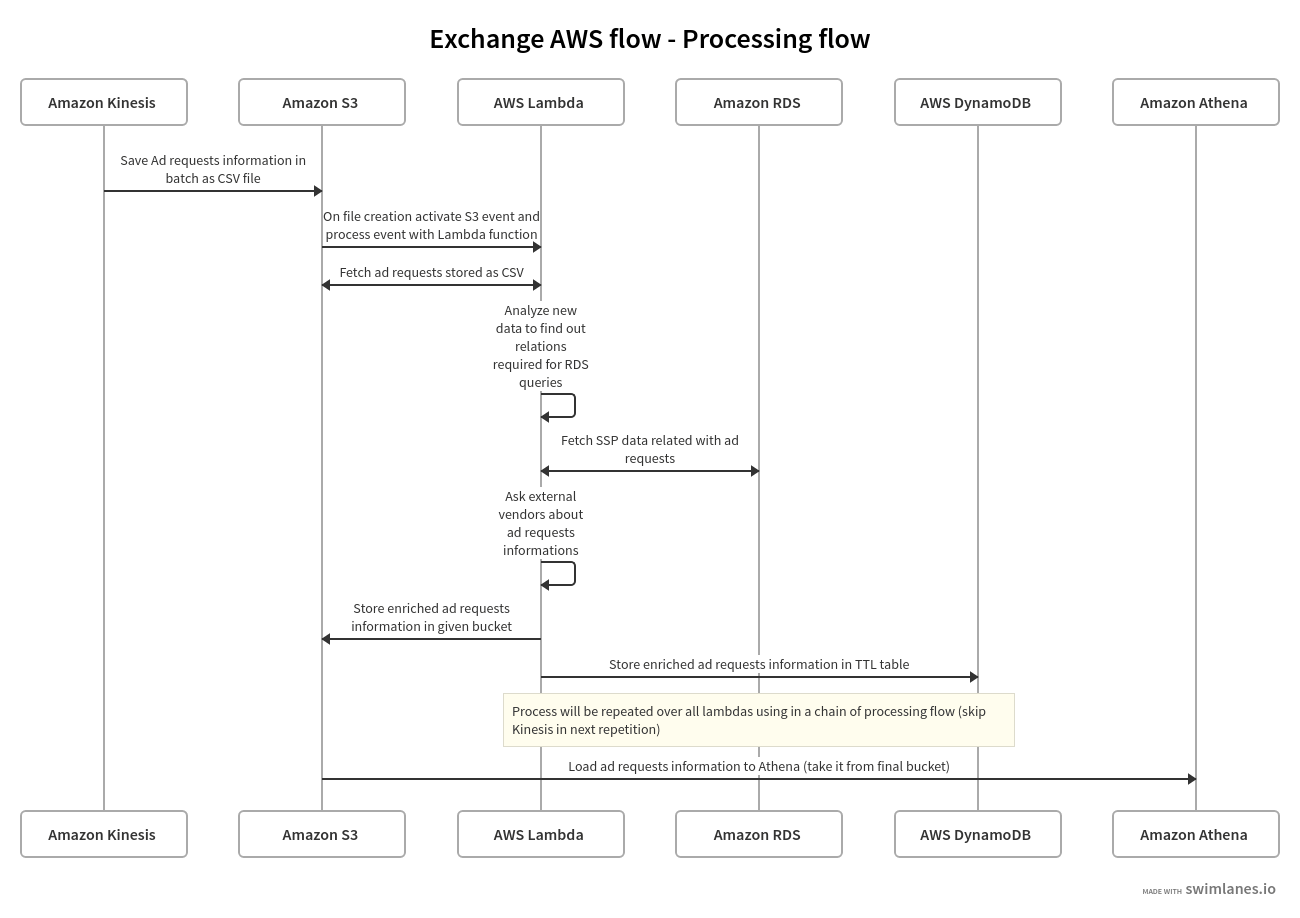
We first start by saving data from AWS Kinesis in S3 buckets, which is done in batches.
Also, whenever a new file is created in this bucket, a new object creation event is triggered and launches an AWS Lambda function. This function is used to process the newly created file.
Depending on the needs of the business, this can be one Lambda function or multiple. Regardless of the number of functions, the process is the same: take data from one bucket, process it via Lambda, and move it to another bucket.
Every Lambda function can have its own logic and way of processing the data.
For example, one process can query a database (e.g. RDS) for the SSP-related information and another can access an external API based on data from the visitor’s request (geolocation, device information, etc).
Finally, the processed data is stored in an S3 bucket.
From there, the data can be queried from Amazon Athena like normal SQL queries.
In parallel, the same data can be stored in DynamoDB tables to speed up the access required in the next step.
Tables with configured TTL should be used to limit the availability of data to some time range (e.g. one week) in order to optimize costs.
Tracking Pixel
In this step, we verify the information acquired about the visitor relative to their real behavior, interactions, and business-related processes performed within the SSP.
When a visitor sees an ad, a pixel is fired (typically from CloudFront) and the requested data (in the URL) is stored as access logs in an S3 bucket.
As in the previous step, we’re using Lambda functions.
This Lambda function, however, tries to get all the information about the ad request, which is stored in the previous step.
Impression logs are once again stored in another S3 bucket, which can then be queried from Amazon Athena.
Post Processing
The final step involves analyzing the data and making it available to external tools.
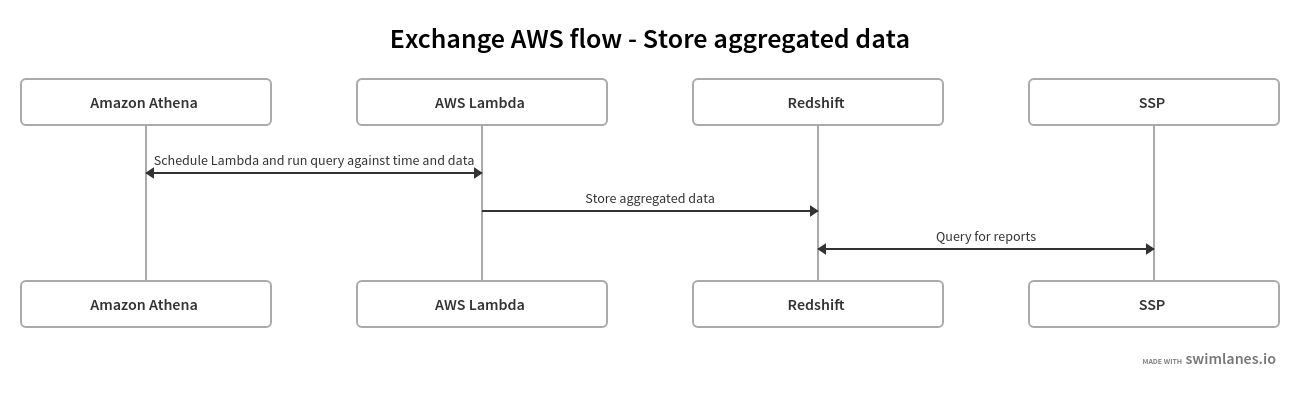
To achieve this, we have to move all the data from Athena (in an aggregated form) to Redshift, which is great for aggregating and processing large amounts of data.
From there, the data can be queried from an SSP interface, allowing publishers and AdOps to view reports on the SSP’s dashboard or in other data visualization tools.
Again, we are using AWS Lambda functions, launched in one minute intervals.
Key Takeaways
To wrap up this article, I’d like to leave you with the main takeaways:
- AWS is an ideal solution for processing large amounts of data very quickly without having to do much coding. Its managed services also greatly reduce the maintenance burden on developers.
- In our experience, we’ve found that it’s the ideal choice for building AdTech platforms as you can easily scale the application (via auto scaling), as well as bring new products to market sooner.
We Can Help You Build an Ad Exchange
Our AdTech development teams can work with you to design, build, and maintain a custom-built ad exchange for any programmatic advertising channel.





