
The programmatic advertising industry has been consumed with news about Google Chrome’s Privacy Sandbox since it was first announced as a replacement for third-party cookies in Chrome in January 2020.
Important Update
On January 25, 2022, Google Chrome announced that it would be retiring FLoC and replacing it with a new standard called Topics API. In this blog post, we explain how FLoC is and answer some common questions about how it was supposed to work.
To learn more about Topics API, read our blog post.
Although there are many standards and APIs in the Privacy Sandbox, the one that’s received the most attention was FLoC.
From the time it was introduced to the time it was shut down, FLoC received both good and bad press, from it being as effective at reaching audiences as third-party cookies to privacy concerns raised by companies like Mozilla, the EFF, and DuckDuckGo.
Even though FLoC has been fairly well documented, it’s a hard concept to understand.
To help you make sense of FLoC and understand how it was designed to work, we’ve put together a list of frequently asked questions.
Frequently Asked Questions (FAQs) About Google Chrome’s FLoC
What was Google Chrome’s FLoC?
Google Chrome’s Federated Learning of Cohorts (FLoC) was one of the standards in the Privacy Sandbox. Specifically, FLoC was designed to run audience targeting but in a much more privacy-friendly way than how it is done currently with third-party cookies. Instead of showing ads to individuals, FLoC would display ads to people based on their cohort, which is a number assigned to a user’s browser.
Web browsers would be placed into cohorts based on their web-browsing behavior. Advertisers would then be able to display ads to those cohorts. For example, cohort 4872 could relate to people interested in tennis. Advertisers could then show ads for tennis equipment to browsers with that cohort.
How did FLoC work and how were cohorts created?
The general concept was that FLoC would incorporate on-device processing and machine learning to place web browsers into a certain cohort based on the websites they visited.
To provide adequate levels of privacy, FLoC used SimHash — a technique for quickly estimating how similar two sets are — and k-anonymity — a technique used to anonymize data.
Source: Web.dev
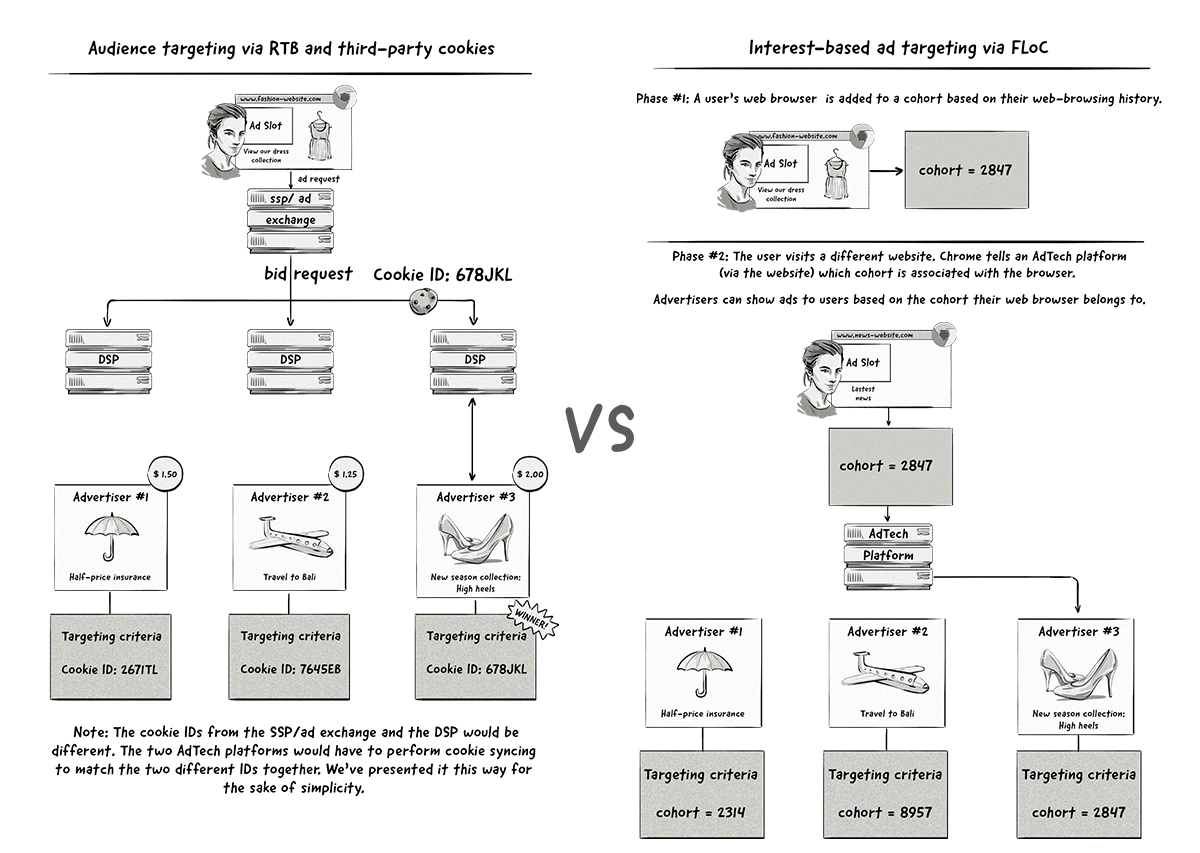
How did FLoC differ from how audience targeting is done now with third-party cookies?
AdTech companies have been able to identify individuals across different websites for over a decade by storing a unique ID inside third-party cookies. From there, they’ve been able to help their clients (advertisers and publishers) show ads to people based on their web-browsing history, content they’ve interacted with, and other factors.
While this has enabled 1:1 personalized ad targeting, it has brought with it a number of privacy concerns.
Users and privacy advocates have been condemning this practice for years and, recently, governments and tech companies, like Apple, have been addressing these privacy issues.
Even Google, a company whose revenue is largely derived from advertising, has made a number of changes to address these privacy concerns.
The standards and APIs in the Privacy Sandbox are examples of Google’s commitment to move away from the current way of running programmatic advertising processes and towards new, privacy-friendly alternatives.
FLoC was designed to address the privacy concerns originating from 1:1 personalized ad targeting by showing ads to users based on their web-browsing history, rather than any specific actions (e.g. clicks and purchases), and doing it on a group level, instead of an individual level (i.e. with user-level identifiers).
In short, audience targeting with third-party cookies is done by identifying individual users and tying together their behavior, interests, and actions with a unique ID. Audience targeting with FLoC was going to be done by showing ads to users based only on their web-browsing history and not using any user-level IDs to identify them.
FLoC also talked about assigning a cohort ID to web browsers instead of individual users. For this reason, we’ll be referring to web browsers instead of users in this blog post.
Was FLoC more effective at reaching an audience than third-party cookies?
During its initial tests, Google claimed that FLoC was 95% as effective as third-party cookies at reaching audiences.
Reactions to these results were mixed, with a fair dose of skepticism.
Google has also come under fire from antitrust regulators about the lack of transparency with its testing.
Google’s testing aside, the effectiveness of FLoC compared to audience targeting via third-party cookies would depend on how well the cohorts aligned with the user’s interests.
There are arguments both for and against whether FLoC was more effective than third-party cookies at reaching an audience. But in July 2021, Google suspended development of FLoC.
We Can Help You Build an AdTech Platform
Our AdTech development teams can work with you to design, build, and maintain a custom-built AdTech platform for any programmatic advertising channel.
Was FLoC going to be implemented into other web browsers apart from Google Chrome?
Every major browser declined implementing FLoC due to fingerprinting concerns and doubts about GDPR compliance.
Apart from web browsers, other websites have also come out and said that they’ll either block FLoC or are considering it. A contributor from WordPress called FLoC a “security concern”. If WordPress decides to block FLoC by default, then it would have rendered FLoC useless.
When was Google Chrome’s FLoC supposed to be released?
In March 2021, Google started the testing phase of FLoC in the Chrome browser. Four months later, after a wave of criticism resulting in declining technology adoption by major competitors, further development of FLoC was suspended. Chrome 93 was the first FLoC-free version of the browser.
Feedback from FLoC’s failure served as the basis for a new proposal from Google Chrome: Topics API.
The official announcement on Topics API was published on January 25, 2022.
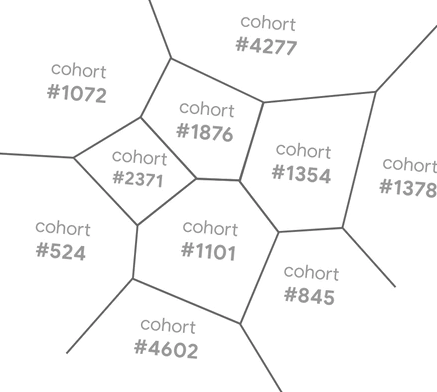
What is a cohort and how was is suppose to be generated?
A cohort represents a group of web browsers that have similar web-browsing history.
For example, one web browser might have visited example.com, news-site.com, and sports-site.com and another web browser might have visited publisher.com, news-site.com, and golf-site.com.
Even though these two browsers didn’t visit the exact same websites, their web-browsing history would have been similar enough to place them in the same cohort. This is a highly simplified version of how cohorts would be assigned to web browsers. Cohorts were to be assigned to web browsers via machine learning algorithms.
Each cohort was to be assigned a cohort ID – a short number such as 7289.
Don’t think of a cohort as a collection of people. Instead, think of a cohort as a grouping of browsing activity.
Source: Web.dev
How many cohorts were meant to be available?
It was not defined how many cohorts were meant to be available. A few hundred was meant to be the maximum.
How many browsers were meant to be in one cohort?
To preserve user privacy and make it hard for companies to identify individual members of a cohort, each cohort was to contain thousands of web browsers.
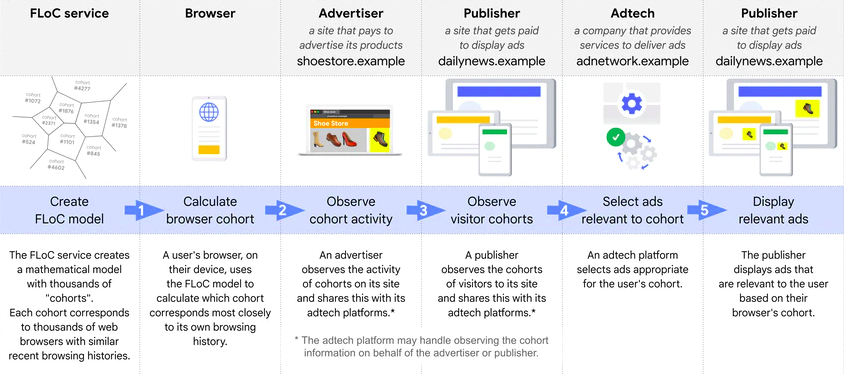
How were advertisers able to show ads to the cohorts?
Advertisers could have observed the behavior of the cohorts on their website and pass this information to their AdTech partners. From there, AdTech companies would have been able to determine what the various cohorts are interested in based on the behavior displayed on websites.
For example, if an ecommerce store (advertiser) observed that web browsers with the cohort ID 3521 viewed their range of smart TVs, then they could have informed their AdTech partners that they want to show ads for their smart TVs to browsers with the cohort 3521.
How were publishers meant to implement FLoC into their websites?
Publishers, as well as advertisers wanting to observe the cohorts on their websites, could have implemented FLoC by calling the FLoC API:
const { id, version } = await document.interestCohort();
console.log('FLoC ID:', id);
console.log('FLoC version:', version);
The API was to return the cohort ID and the FLoC/browser version:
{
id: "14159",
version: "chrome.1.0"
}
Once publishers received the cohort ID, they could then have passed it to their AdTech partners to match the cohort ID with the ones advertisers were wanting to reach.
What role would AdTech companies have played in the targeting and delivery of FLoC-based campaigns?
AdTech companies could have helped publishers monetize their inventory and helped advertisers reach their target audiences by matching the cohorts observed by advertisers with the cohorts present on websites.
In other words, instead of matching IDs in third-party cookies, they could have been matching cohort IDs between advertisers and publishers.
For example, if an AdTech company had observed that browsers with the cohort ID of 3521 had been interested in smart TVs, then they could have helped advertisers show ads for smart TVs on websites where this ID is present.
Could publishers have opted out or stopped FLoC data from being collected on their websites?
Publishers could have opted out of FLoC by sending the following HTTP response header:
Permissions-Policy: interest-cohort=()Browsers that visited the publisher wouldn’t have been included in the FLoC calculations.
Did cohorts contain sensitive categories, e.g. race, religion, sexuality, and medical history?
FLoC was aiming to exclude sensitive categories when generating cohorts by evaluating the domain, URL, and contents of a web page and deciding whether it relates to a sensitive category and then subsequently excluding it from being added to a cohort.
However, there weren’t enough safeguards in place to prevent this from happening, and this was one of the main criticisms of FLoC.
The clustering algorithm used to construct the FLoC cohort model is designed to evaluate whether a cohort may be correlated with sensitive categories, without learning why a category is sensitive. Cohorts that might reveal sensitive categories such as race, sexuality, or medical history will be blocked. In other words, when working out its cohort, a browser will only be choosing between cohorts that won’t reveal sensitive categories.
Source: Web.dev
Why were people saying that FLoC doesn’t protect user privacy?
Even though FLoC was designed to be a privacy-friendly way of running audience targeting, it received its fair share of criticism.
Firstly, because it was still a form of personalized advertising, many privacy advocates said that it isn’t privacy-friendly as it enables advertising based on a user’s browser history. Many privacy advocates didn’t want personalized ad targeting to exist at all.
Secondly, it was also possible for companies to identify which cohort you belong to by matching PII (e.g., email addresses) with your cohort ID, leading to many privacy concerns around device fingerprinting and essentially removing the privacy protections that FLoC was designed to provide.
Thirdly, it generated an antitrust response in multiple countries and controversies about GDPR compliance.
We Can Help You Build an AdTech Platform
Our AdTech development teams can work with you to design, build, and maintain a custom-built AdTech platform for any programmatic advertising channel.






