Google’s Privacy Sandbox is an initiative designed to protect user privacy. Fueled by privacy-enhancing technologies, it aims to deliver an excellent user experience and fulfill advertisers’ needs to run effective ad campaigns.
Key Points
- Google’s Privacy Sandbox is a set of standards that enhance online privacy while supporting digital advertising businesses and ad-supported websites.
- Google Chrome developed Privacy Sandbox to tackle privacy concerns related to third-party cookies. The company was to phase them out while rolling out Privacy Sandbox, but it decided not to do this and will soon introduce an option for users to allow or decline cookies from their browser.
- The main advertising standards within the Privacy Sandbox include the Private Aggregation API, Attribution Reporting API, Topics API, and Protected Audience API (PAAPI).
What Is Google’s Privacy Sandbox?
In the AdTech context, Google’s Privacy Sandbox is an initiative that aims to provide an alternative way to deliver targeted ads to users and measure the performance of ad campaigns. It includes several standards built with privacy-enhancing technologies, such as differential privacy and on-device processing, that carry out the key programmatic advertising processes while strengthening user privacy.
To adopt a standard, each proposal in the Privacy Sandbox undergoes tests. To be more specific, the W3C Improving Web Advertising Business Group, in collaboration with Google Chrome, AdTech companies, agencies, publishers and Google’s advertising teams, works on the new privacy standards.
Since being introduced in 2019, some Privacy Sandbox standards have been partially changed, some were closed, and some are set to work as they are.
Why Has Google Created Its Privacy Sandbox?
The General Data Protection Regulation (GDPR) regulation, introduced in 2018, has highlighted the privacy concerns associated with data collection, driving the need for more privacy-conscious alternatives which the Privacy Sandbox aims to be.
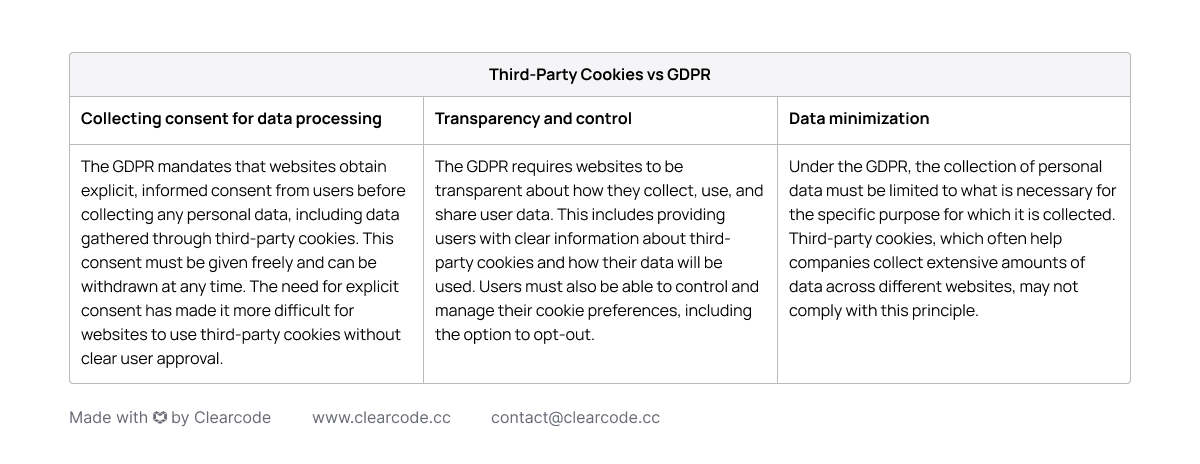
In addition to the GDPR and other privacy regulations, tech companies have also made changes to their privacy policies to strengthen user privacy.
In the same year the GDPR was rolled out, major web browsers — primarily, Safari and Firefox — started to change their privacy settings to restrict cross-site identification. But they didn’t offer any alternative to cookies; They simply shut down the possibility of cross-site tracking for publishers and media buyers.
Alphabet, Google’s parent company, generates a majority of its revenues from advertising. By allowing Chrome to use third-party cookies, Google can still generate revenue from its display advertising business. Unlike Firefox and Safari, which simply restricted these cookies, Alphabet chose not to eliminate them without offering an alternative. Nevertheless, it needed to reduce cross-site tracking in Chrome, mainly to meet the growing demands of privacy advocates and Internet users.
Chrome initially introduced the SameSite attribute, requiring website developers and AdTech firms to specify their third-party cookies with SameSite=None to comply with this attribute. This change makes it easier for users to block and remove third-party cookies.
However, the SameSite attribute alone wasn’t sufficient. Therefore, in 2019, Google Chrome developed a set of open standards to enhance user privacy, known as the Privacy Sandbox.
Google planned to phase out third-party cookies while rolling out Privacy Sandbox, but it decided not to do this and will soon introduce an option for users to allow or decline cookies from their browsers.
The Goals of Privacy Sandbox
From the technical point of view, the Privacy Sandbox has three primary goals:
- Substitute cross-site tracking mechanisms that currently rely on third-party cookies.
- Introduce a mechanism that allows users to make a choice whether to allow for tracking or not.
- Address unethical tracking techniques, such as fingerprinting.
The Privacy Sandbox uses a privacy-first design philosophy with advanced techniques like federated learning and differential privacy, which enables targeted advertising without tracking individual user behavior across websites.
It also reduces the risk of large-scale data breaches by storing data locally on a user’s device through decentralized data handling.
We Can Help You Build an AdTech Platform
Our AdTech development teams can work with you to design, build, and maintain a custom-built AdTech platform for any programmatic advertising channel.
Why Is Privacy Sandbox Important to the AdTech Industry?
Google’s Privacy Sandbox aims to conduct advertising processes in a controlled environment, which is in contrast to the way these activities are currently conducted.
The intention is to create a balance between user privacy and an ad-supported web by addressing the privacy concerns from users, privacy advocates and regulators.
By promoting contextual targeting, Privacy Sandbox shifts the focus from a user’s behavior to the webpage’s content.
In simple terms, Google’s Privacy Sandbox wants to design new privacy-friendly standards for the ad-supported web.
What Are the Key Advertising Standards in Google’s Privacy Sandbox?
The Privacy Sandbox includes several standards aimed at:
- Strengthening cross-site privacy boundaries
- Showing relevant content and ads
- Measuring digital ads
- Preventing covert tracking
- Combating spam and fraud on the web
Here are the standards essential for the AdTech industry:
- Private Aggregation API — a standard for cross-site data reporting
- Attribution Reporting API — a standard for reporting on ad campaigns effectiveness
- Topics API (initially FLoC) — a standard for interest-based advertising
- Protected Audience API (initially TURTLEDOVE, then renamed to FLEDGE) — a standard for remarketing

Private Aggregation API
This API’s main focus is to aggregate and report on cross-site data in a privacy-preserving manner. Developers can create aggregate data reports using the Private Aggregation API, which is powered by data from the Protected Audience API and cross-site data from Shared Storage.
As of 2024, the API performs one operation, sendHistogramReport(), which allows marketers to gather data across users using defined aggregation keys. This operation returns a noised aggregated result in the form of a summary report.
For example, based on Shared Storage demographic and geographic data, a marketer can create a histogram showing the approximate number of users in a particular location who have seen their ads across different websites.
In the future, additional operations might be supported by this API.
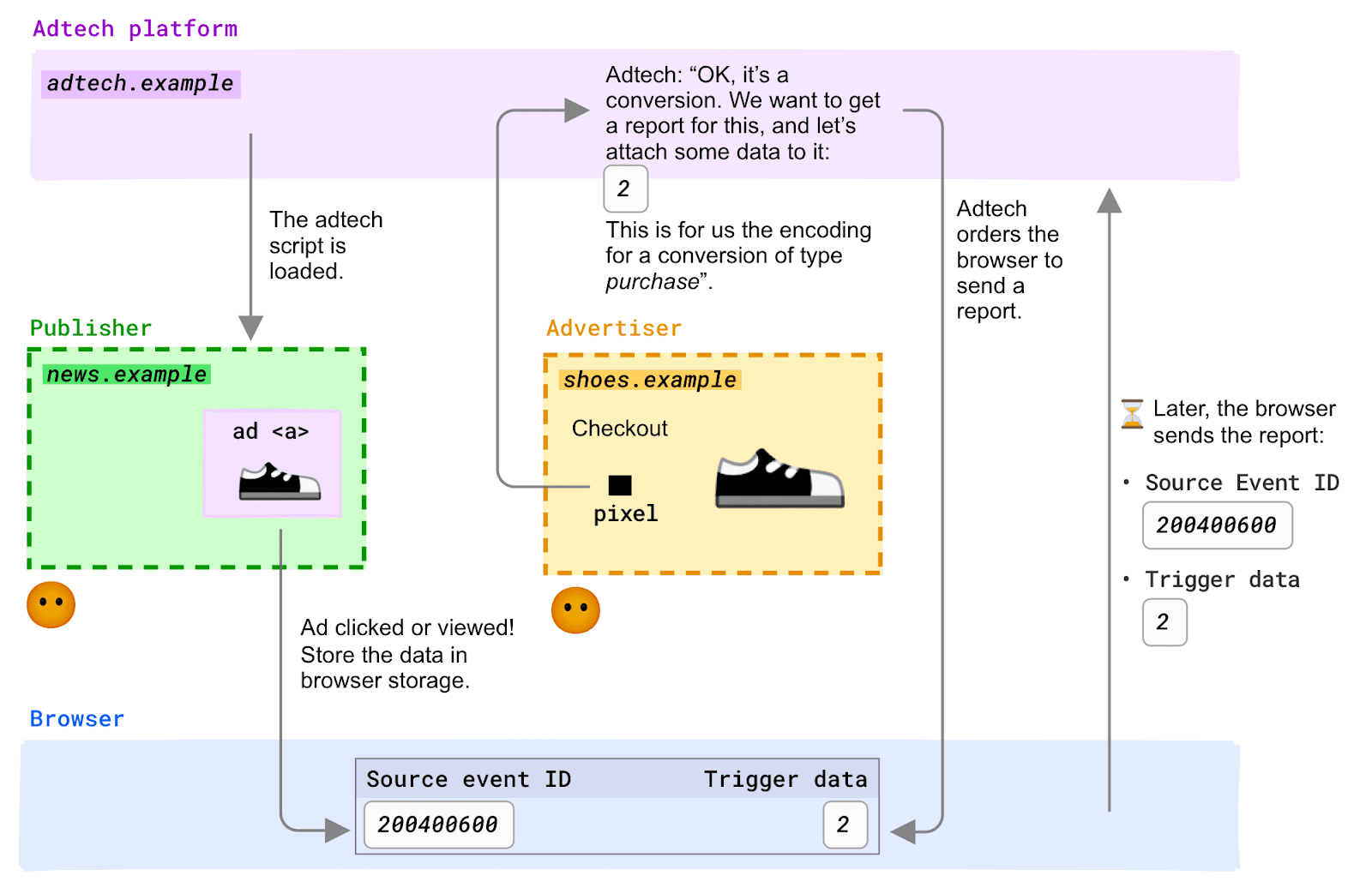
Attribution Reporting API
The Attribution Reporting API enables advertisers and AdTech providers to measure conversions without third-party cookies.
These conversions include:
- Ad clicks and views.
- Ads in a third-party iframe, such as those on a publisher site using a third-party AdTech provider.
- Ads in a first-party context, like ads on a social network or a search engine results page, or a publisher serving their own ads.
Private Aggregation API vs Attribution Reporting API
The Private Aggregation API is tailored for cross-site measurements, working alongside APIs like the Protected Audience API and Shared Storage. It evaluates unified, cross-site events.
The Attribution Reporting API operates independently to measure conversions and correlating data from separate impression and conversion events.
Topics API (initially FLoC)
Google continuously develops and tests Privacy Sandbox solutions to ensure users and advertisers use the most refined standards possible. In the case of creating an interest-based advertising standard, Google initially experimented with cohorts (FLoC) but eventually shut the project down and replaced it with a solution utilizing broader categories of interests (Topics API).
Federated Learning of Cohorts (FLoC): An experimental technology for targeted advertising that grouped users into cohorts based on similar browsing patterns, avoiding individual tracking. Despite its goal to reduce traditional third-party cookies and cross-site tracking, FLoC faced criticism and privacy concerns, leading to its replacement.
Topics API: Replaced FLoC, using broader categories of interests instead of detailed individual profiles, allowing for personalized advertising without extensive tracking.
Protected Audience API (initially TURTLEDOVE and FLEDGE)
The advertising standards in the Privacy Sandbox are also developed by incorporating the best solutions. Protected Audience API (PAAPI), built on top of several advertising technologies, is an example of this development.
TURTLEDOVE: The first standard introduced for remarketing in the Privacy Sandbox, designed to enable users to re-engage with ads they previously interacted with while safeguarding privacy. Details about user interests were stored by the browser rather than the advertiser, preventing linking interests to personal details. This was also the initial name for the standard, then changed to FLEDGE.
FLEDGE: An early prototype of ad-serving within TURTLEDOVE, incorporating various proposals from independent AdTech companies and Google Chrome itself.
Key FLEDGE components included:
- Criteo’s SPARROW proposal: Allowed frequency capping, A/B testing, and optimization via a third-party server.
- Chrome’s Dovekey: Introduced a third-party key-value server for handling bidding and auction processes.
- Chrome’s Fenced Frames: Enabled ads to load on a web page without revealing the displayed ad to the rest of the page.
- NextRoll’s TERN: Improved TURTLEDOVE by allowing publishers to control auction dynamics and encouraging second-price auctions.
- Magnite’s PARROT: Gave publishers control of the auction decisioning using Fenced Frames.
In 2023, FLEDGE was renamed to Protected Audience API to better reflect the project’s primary goals.
How Will Key Programmatic Advertising Processes Work in Google’s Privacy Sandbox?
Ad Targeting
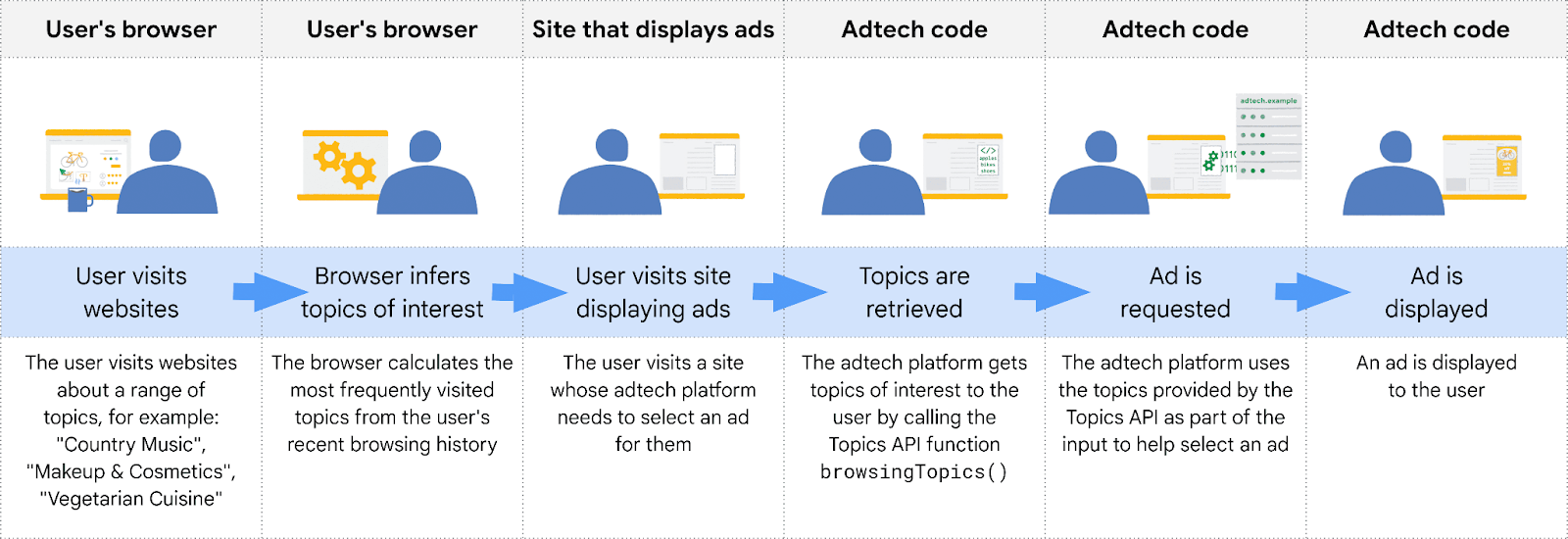
The Topics API observes and saves topics that interest users based on their online activities, with the entire process conducted on the user’s device within their browser. Advertisers and ad platforms can access these topics without revealing other details about the user’s browsing history.
Topics are categorized into lists such as Arts & Entertainment or Business & Industrial. To maintain privacy, topics are public, human-curated, and regularly updated. Chrome’s test list excludes sensitive topics like race or sexual orientation.
For the top 50,000 sites, Chrome manually matches website names to topics. For other sites, it uses a machine learning model to infer topics from site names.
This is how the Topics API works:
Frequency Capping
Frequency capping limits the number of times a user sees the same ad within a given timeframe, such as 10 ad impressions over 24 hours. The Protected Audience API manages frequency capping by storing counts of ad events on devices and filtering ads based on preset rules.
Each device, ad technology, and ad type has unique counts. Ads must have specific codes for counting views or clicks. The Protected Audience API tracks these counts, updating them when views or clicks occur, and saves them on the device for a set period.
The ad selection process of the Protected Audience API considers these counts along with factors like retargeting and context, ensuring effective frequency capping for all ad requests.
Measurement and Attribution
Within the Privacy Sandbox, advertisers can measure events and correlate conversions.
Event-level reports function as follows: The browser links clicks or views with conversion data set by an ad technology, then sends these reports to a destination with some delay and noise to prevent identity connection across sites.
Summary reports aggregate data for a group of users without linking it to individuals. These reports provide detailed conversion data, such as purchase amounts and cart items, along with options for click and view data. They are less delayed than event-level reports.
Frequently Asked Questions About Google’s Privacy Sandbox
Why are some people criticizing Google’s Privacy Sandbox?
Privacy advocates, the IAB Tech Lab, and the wider programmatic advertising industry criticize the Privacy Sandbox for several reasons, including advertising effectiveness, media measurement, brand safety, and transparency.
According to the IAB Tech Lab’s gap analysis report, the Privacy Sandbox would severely inhibit many current forms of digital advertising. The report highlights issues with the loss of runtime data, which could lead to brand safety problems.
The IAB Tech Lab also argues that transitioning to the Privacy Sandbox would require major infrastructural changes and could negatively impact AdTech companies, publishers, and advertisers.
Google’s dominant position in the digital advertising market raises antitrust concerns. Critics worry that the Privacy Sandbox could further consolidate Google’s control over online advertising by centralizing data and targeting tools within its ecosystem, potentially stifling competition and innovation.
What are some of the pros and cons of Google’s Privacy Sandbox?
Pros:
- The Privacy Sandbox aims to improve user trust and compliance with privacy regulations by reducing cross-site tracking and providing more transparent user controls.
- It offers technologies that enable targeted advertising while securing user privacy.
Cons:
- Google’s control over the Privacy Sandbox standards could consolidate its market position, potentially disadvantaging smaller AdTech firms and publishers, which is one of the areas currently under investigation by the British Competition and Markets Authority (CMA).
- There are concerns about the effectiveness of the Privacy Sandbox technologies in balancing privacy and advertising needs, leading to skepticism among AdTech stakeholders.
- Publishers, AdTech companies, and advertisers must prepare their digital environments before the introduction of the Privacy Sandbox. Publishers need to create addressable audiences, AdTech companies need to adapt their technology stacks, and advertisers need to review their relationships with publishers to focus on first-party data.
Will Google use it in its own advertising platforms (e.g., DV360)?
Google hasn’t provided a definitive timeline for when a UI for testing the Privacy Sandbox on DV360 might be developed. However, it has stated that buyers do not need to take direct action to test within Google ad platforms.
Instead, Google conducts scaled testing for the buy-side using global slices of traffic to generate learnings applicable to its entire customer base. Other AdTech firms are also testing the Privacy Sandbox, enabling the buy-side to test even if DV360 does not facilitate this process.
Is Google’s Privacy Sandbox effective in reaching a target audience and maintaining high CPMs?
Google’s Privacy Sandbox may not effectively reach target audiences or maintain high CPMs due to:
- A lack of 1-to-1 identification: Advertisers will not be able to identify their target audience and display perfectly aligned ads.
- Ad campaigns performance issues: The effectiveness of ad campaigns will be less accurate due to the inability to properly connect ad views and clicks to conversions.
Is Google’s Privacy Sandbox only available in Chrome or is it also available on Android?
The Privacy Sandbox functionalities are being rolled out across both Chrome and Android-powered devices. The goal is to phase out third-party cookies in Chrome and mobile IDs on Android devices to limit cross-site and cross-app tracking and strengthen user privacy.
What role does the UK’s Competition and Markets Authority (CMA) play in the release of Google’s Privacy Sandbox?
The UK’s Competition and Markets Authority (CMA) is investigating Google’s Privacy Sandbox proposals to ensure they don’t disrupt competition. The aim of the CMA’s investigation is to address both privacy concerns and potential impacts on publishers and the digital advertising market.
Will Google’s Privacy Sandbox be available in other web browsers like Safari, Firefox, and Edge?
In September 2017, Safari introduced a privacy feature called Intelligent Tracking Prevention (ITP), which automatically blocks third-party cookies and restricts the duration of first-party cookies and local storage.
Similarly, Firefox launched a privacy feature called Enhanced Tracking Protection (ETP), which defaults to blocking third-party cookies and device fingerprints.
While neither of these browsers has announced plans to adopt Google Chrome’s Privacy Sandbox, the possibility cannot be entirely dismissed.
We Can Help You Build an AdTech Platform
Our AdTech development teams can work with you to design, build, and maintain a custom-built AdTech platform for any programmatic advertising channel.