
Data platforms have been a key part of the programmatic advertising and digital marketing industries for well over a decade.
Platforms like customer data platforms (CDPs) and data management platforms (DMPs) are crucial for helping advertisers and publishers run targeting advertising campaigns, generate detailed analytics reports, run attribution, and help them better understand their audiences.
Another key component of data platforms is a data lake, which is a centralized repository that allows you to store all your structured and unstructured data in one place. The data collected by a data lake can then be passed to a CDP or DMP and used to create audiences, among other things.
In this blog post, we’ll look at what CDPs, DMPs, and data lakes are, outline situations where building them makes sense, and provide an overview of how to build them based on our experience.
Why Should You Build a CDP or DMP?
Although there are many CDPs and DMPs on the market, many companies require their own solution to provide them with control over the collected data, intellectual property, and feature roadmap.
Here are a couple of situations where building a CDP or DMP makes sense:
- If you’re an AdTech or MarTech company and are wanting to expand or improve your tech offering.
- If you’re a publisher and want to build a walled garden to monetize your first-party data and allow advertisers to target your audiences.
- If you’re a company that collects large amounts of data from multiple sources and want to have ownership of the tech and control over the product and feature roadmap.
We Can Help You Build a Customer Data Platform (CDP)
Our AdTech development teams can work with you to design, build, and maintain a custom-built customer data platform (CDP) for any programmatic advertising channel.
What Is a Customer Data Platform (CDP)?
A customer data platform (CDP) is a piece of marketing technology that collects and organizes data from a range of online and offline sources.
CDPs are typically used by marketers to collect all the available data about the customer and aggregate it into a single database, which is integrated with and accessible from a number of other marketing systems and platforms used by the company.
With a CDP, marketers can view detailed analytics reports, create user profiles, audiences, segments, and single customer views, as well as improve advertising and marketing campaigns by exporting the data to other systems.
View our infographic below to learn more about the key components of a CDP:
What Is a Data Management Platform (DMP)?
A data management platform (DMP) is a piece of software that collects, stores, and organizes data collected from a range of sources, such as websites, mobile apps, and advertising campaigns. Advertisers, agencies, and publishers use a DMP to improve ad targeting, conduct advanced analytics, look-alike modeling, and audience extension.
View our infographic below to learn more about the key components of a DMP:

What Is a Data Lake?
A data lake is a centralized repository that stores structured, semi-structured and unstructured data, usually in large amounts. Data lakes are often used as a single source of truth. This means that the data is prepared and stored in a way that ensures it’s correct and validated. A data lake is also a universal source of normalized, deduplicated, aggregated data that is used across an entire company and often includes user-access controls.
Structured data: Data that has been formatted using a schema. Structured data is easily searchable in relational databases.
Semi-structured data: Data that doesn’t conform with the tablature structure of databases, but contains organizational properties that allow it to be analyzed.
Unstructured data: Data that hasn’t been formatted and is in its original state.

Many companies have data science departments or products (like a CDP) that collect data from different sources, but they require a common source of data. Data collected from these different data sources often requires additional processing before it can be used for programmatic advertising or data analysis.
Generally, unaltered or raw-stage data (also known as bronze data) is also available. With this data-copying approach, we are able to perform additional data verification steps on sampled or full data sets. Raw stage is also helpful if, for some reason, we need to process the historical data, which was not entirely transformed.
What’s the Difference Between a CDP, DMP, and a Data Lake?
CDPs may seem very similar to DMPs, as they are all responsible for collecting and storing data about customers. There are, however, certain differences in the way they work.
CDPs primarily use first-party data and are based on real consumer identities generated by collecting and using personally identifiable information (PII). The information comes from various systems in the organization and can be enriched with third-party data. CDPs are mainly used by marketers to nurture the existing consumer base.
DMPs, on the other hand, are primarily responsible for aggregating third-party data, which typically involves the use of cookies. In this way, a DMP is more of an AdTech platform, while a CDP can be considered a MarTech tool. DMPs are mainly used to enhance advertising campaigns and acquire lookalike audiences.
A data lake is essentially a system that collects different types of data from multiple sources and then feeds that data into a CDP or DMP.

Popular Use Cases of a CDP, DMP, and Data Lake
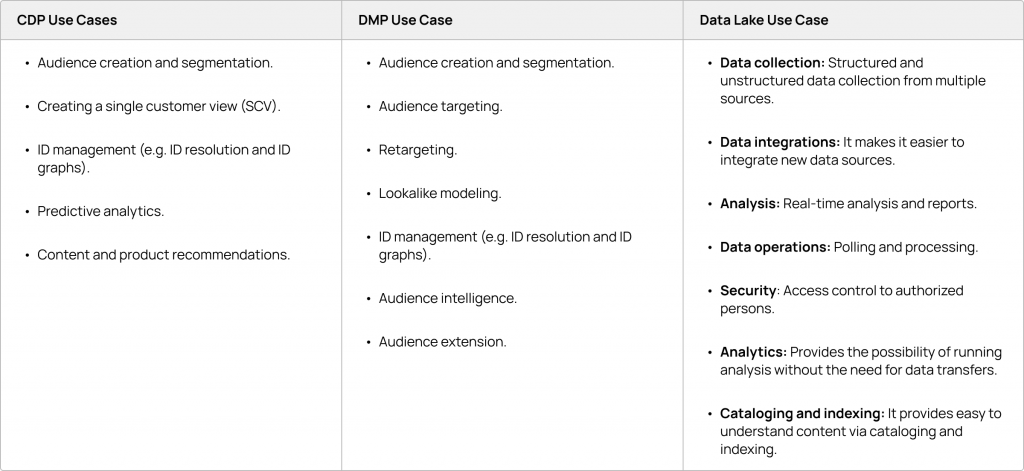
What Types of Data Do CDPs, DMPs, and Data Lakes Collect?
The types of data CDPs, DMPs, and data lakes collect include:
First-Party Data
First-party party data is information gathered straight from a user or customer and is considered to be the most valuable form of data as the advertiser or publisher has a direct relationship with the user (e.g. the user has already engaged and interacted with the advertiser).
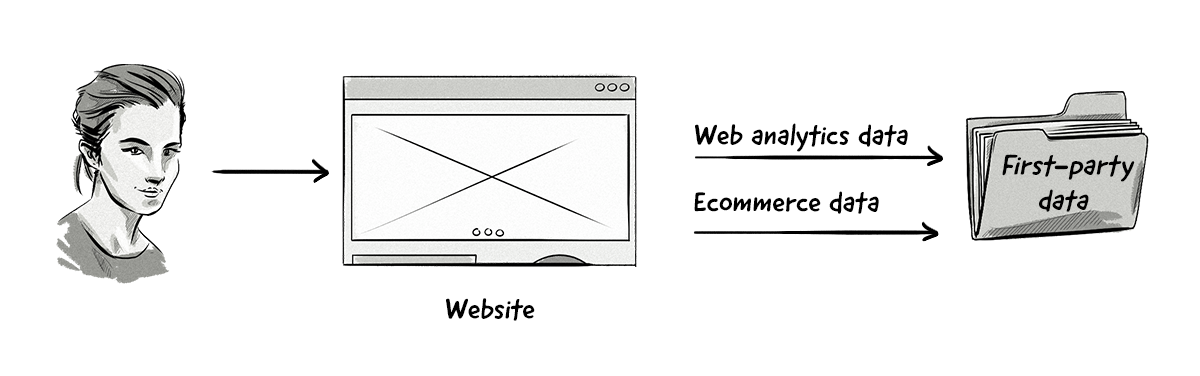
First-party data is typically collected from:
- Web and mobile analytics tools.
- Customer relationship management (CRM) systems.
- Transactional systems.
Second-Party Data
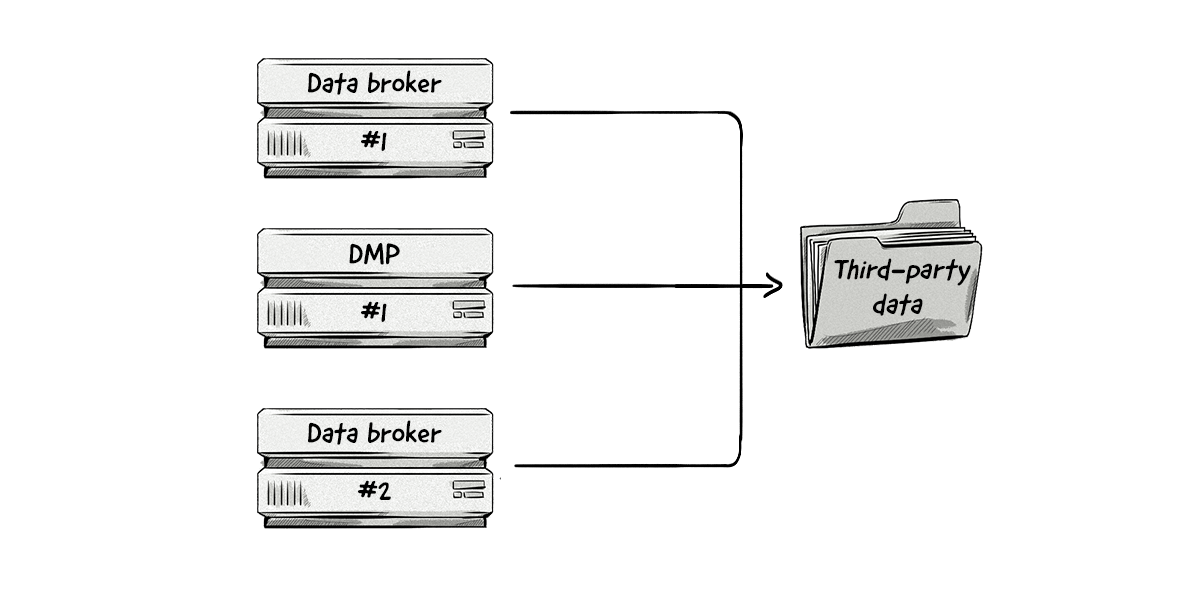
Many publishers and merchants monetize their data by adding third-party trackers to their websites or tracking SDKs to their apps and passing data about their audiences to data brokers and DMPs.
This data can include a user’s browsing history, content interaction, purchases, profile information entered by the user (e.g. gender or age), GPS geolocation, and much more.
Based on these data sets, data brokers can create inferred data points about interests, purchase preferences, income groups, demographics and more.
The data can be further enriched from offline data providers, such as credit card companies, credit scoring agencies and telcos.
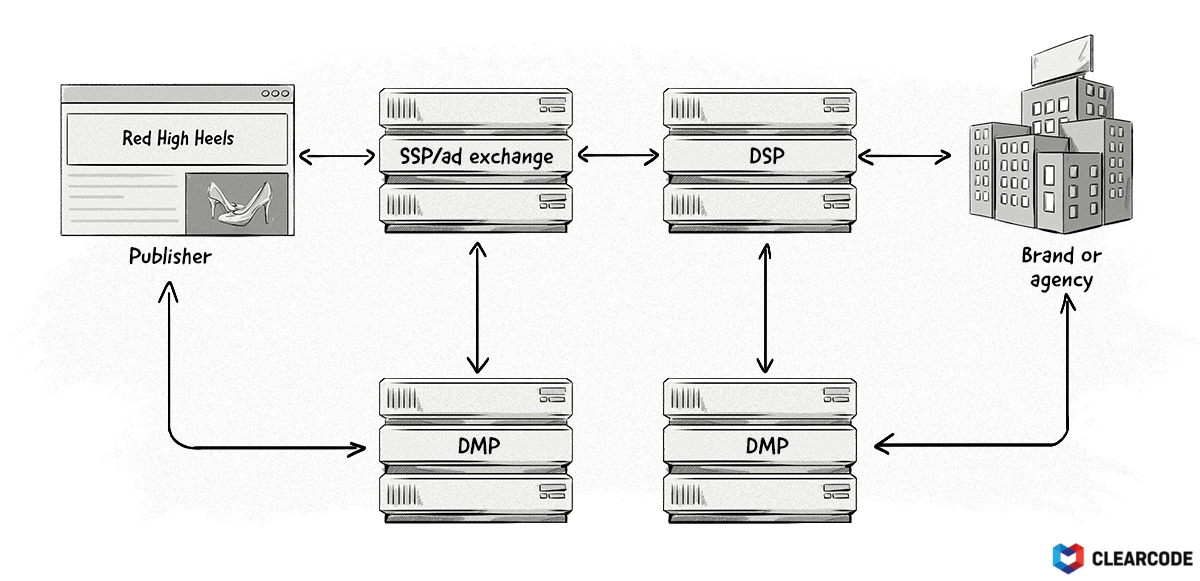
How Do CDPs, DMPs, and Data Lakes Collect This Data?
The most common ways for CDPs, DMPs, and data lakes to collect data are by:
- Integrating with other AdTech and MarTech platforms via a server to server connection or API.
- Adding a tag (aka JavaScript snippet or HTML pixel) to an advertiser or publisher’s website.
- Importing data from files, e.g. CSV, TSV, and parquet.
Common Technical Challenges and Requirements When Building a DMP or CDP
Both CDP and DMP infrastructures are intended to process large amounts of data as the more data the CDP or DMP can use to build segments, the more valuable it is for its users (e.g. advertisers, data scientists, publishers, etc.).
However, the larger the scale of data collection, the more complex the infrastructure setup will be.
For this reason, we first need to properly assess the scale and amount of data that needs to be processed as the infrastructure design will be dependent on many different requirements.
Below are some key requirements that should be taken into account when building a CDP or DMP.
Data-Source Stream
A data-source stream is responsible for obtaining data from users/visitors. This data has to be collected and sent to a tracking server.
Data sources include:
- Website data: JavaScript code on a website is used to check for browser events. If an action is undertaken by a visitor, then the JS code creates a payload and sends it into the tracker component.
- Mobile application data: This often involves using an SDK, which can collect first-party application data. This data may include user identification data, profile attributes, as well as user behaviour data. User behaviour events include specific actions inside mobile apps. Data sent from an SDK is collected by the tracker component.
Data Integration
There are multiple data sources that can be incorporated into a CDP’s or DMP’s infrastructure:
- First-party data integration: This includes data collected by a tracker and data from other platforms.
- Second-party data integration: Data collected via integrations with data vendors (e.g. credit reporting companies), which can be used to enrich profile information.
- Third-party data integration: Typically via third-party trackers, e.g. pixels and scripts on websites and SDKs in mobile apps.
The Number of Profiles
Knowing the number of profiles that will be stored in a CDP or DMP is crucial in determining the database type for profile storage.
Seeing as the profile database is responsible for identity resolution, which plays a key role in profile merging, and for proper segment assignment, it is a key component of the CDP’s or DMP’s infrastructure.
Data Extraction and Discovery
One common use case of a CDP and DMP is to provide an interface for data scientists so they have a common source of normalized data.
The cleaned and deduplicated data source is a very valuable input that can be used to additionally prepare data for machine-learning purposes. This kind of data preparation often requires you to create a data lake, where data is transformed and encoded to a form that can be understood by machines.
There are many types of data transformations, such as:
- OneHotEncoder
- Hashing
- LeaveOneOut
- Target
- Ordinal (Integer)
- Binary
Selecting a suitable data transformation type and designing a good data pipeline for machine learning involves collaboration between the development team and data scientists who analyze the data and provide valuable input regarding the machine-learning requirements.
Additionally, machine learning may be used to create event-prediction models to produce clustering and classification jobs, and aggregate and transform data. This can lead to discovering patterns that may be invisible to a human eye initially, but become quite obvious after applying a transformation (e.g. a hyperplane transformation).
Segments
The types of segments that need to be supported by a CDP’s and DMP’s infrastructure also influence the infrastructure’s design.
The following types of segments can include:
- Attribute-based segments (demographic data, location, device type, etc).
- Behavioral segments based on events (e.g. clicking on a link in an email), and their frequency of actions (e.g. visiting a web page at least three times a month).
- Segments based on classification performed by machine learning:
- Lookalike / affinity:The goal of lookalike/affinity modelling is to support audience extension. Audience extension can be based on a variety of inputs and be driven by similar functions. In the end, you can imagine a self-improving loop where we pick profiles with a lot of conversions and create affinity audiences. This results in an audience with more conversions, which can be used to create more affinity profiles, etc.
- Predictive:The goal of predictive targeting is to use available information to predict the possibility of an interesting event (purchase, app installation, etc.) and to target only the profiles who have a high prediction rate.
Common Technical Challenges and Requirements When Building a Data Lake
Below are some common challenges when building a data lake:
- It’s difficult to combine multiple data sources together to generate any kind of useful insights and actionable data. Usually, IDs are required to bind the different data sources together, but often these IDs are not present or simply don’t match.
- It’s often hard to know what data is included in a given data source. Sometimes the data owner doesn’t even know what kind of data is there.
- There is also a need to clean up the data and reprocess it in case of an ETL pipeline failure, which will happen from time to time. This needs to be done either manually or automatically. Databricks Delta Lake has an automatic solution since their delta tables comply with ACID properties. AWS is also implementing ACID transactions in one of their solutions (governed tables), but it’s only available in one region at the moment.
In the first step of processing, data is extracted and loaded into the first raw stage. After the first stage, multiple data lake stages are often available, depending on the use case.
Usually, the second step carries out various data transformations, like deduplication, normalisation, column prioritisation, and merging. The following steps perform additional layers of data transformations, for example, business-level aggregations required for the data science team or for reporting purposes.
By incorporating data lake components from AWS, such as Amazon Lake Formation, which uses a well-known S3 storage mechanism, with Amazon Glue or Amazon EMR for the ETL data pipeline purpose, we are able to create a centralized, curated, and secured data repository.
On top of Amazon Lake Formation, there is a common interface called Amazon Athena that can be used between multiple infrastructure components, and provides a unified data access method to Amazon Lake Formation.
Additionally, by using IAM security methods, an additional layer of proper access-level controls can be added to the data lake.
If the data lake is properly designed and created, access to the data can be optimized for costs.
Also, thanks to the final aggregate level, we are allowed to perform the required operations only once during the ETL pipeline when required.
An Example of How to Build a CDP, DMP, and Data Lake
Download the full version of this article to see an example of a CDP/DMP and data lake development project.
The full version includes:
- A list of the main features of a CDP/DMP and data lake.
- An example of the architecture setup on AWS.
- The request flows.
- The Amazon Web Services we used.
- A cost-level analysis of the different components.
- Important considerations.
We Can Help You Build a Customer Data Platform (CDP)
Our AdTech development teams can work with you to design, build, and maintain a custom-built customer data platform (CDP) for any programmatic advertising channel.






